Introduction to torch.compile and How It Works with vLLM
Note
This blog originated from our biweekly vLLM office hours, a community forum hosted by Red Hat with vLLM project committers and the UC Berkeley team. Each session covers recent updates, a deep dive with a guest speaker, and open Q&A. Join us every other Thursday at 2:00 PM ET / 11:00 AM PT on Google Meet, and get the recording and slides afterward on our YouTube playlist.
Introduction
Fast large language model (LLM) inference today requires executing models as efficiently as possible across diverse hardware, workloads, and scale. Efficient execution requires heavily optimized kernels that often require hand-tuning for different models and platforms. torch.compile, PyTorch’s just-in-time (JIT) compiler generates optimized kernels automatically, which makes PyTorch code run significantly faster without requiring developers to manually optimize kernels across all supported hardware platforms.
For vLLM, the de-facto open-source inference engine for portable and efficient LLM inference, torch.compile isn’t just a performance enhancer. It’s a core component that shifts the responsibility of optimization from model developers to the compiler. Instead of requiring changes to model definitions, optimizations are applied during compilation, enabling cleaner separation of concerns and achieving maximal performance. In this post, we’ll walk through how torch.compile works, how it’s integrated into vLLM, and how vLLM uses custom compiler passes to maximize performance. We will also discuss ongoing and future work on the torch.compile integration in vLLM to further improve its usability and performance.
What Is torch.compile?
torch.compile lets you optimize PyTorch code with minimal effort: using torch.compile is as simple as applying a decorator to a function or torch.nn.Module. torch.compile automatically captures tensor operations into a computation graph that it then generates optimized code for.
In the following example, torch.compile produces a single fused kernel for all pointwise operations in function fn. It captures and compiles the function just-in-time, potentially recompiling if any of the capture conditions (e.g. input shapes) change.

Figure 1: torch.compile is a JIT compiler for PyTorch code. You can wrap functions, nn.Modules, and other callables in torch.compile.
There are multiple ways to use torch.compile. You can use it as a kernel generator (like in Figure 1), where we compile a function. But you can also apply torch.compile to your full nn.Module model or submodules of it. Depending on the structure of the model and your requirements (e.g. compile times), we recommend applying torch.compile in different places.
Why Use torch.compile?
One way of optimizing models is to write custom CPU/CUDA operations that perform the same operations as in the model but faster. Writing custom kernels for every model is time-consuming and requires a deep understanding of performance and hardware. torch.compile gets you a decent amount of the way to peak performance with almost no additional engineering effort. For example, PyTorch’s open source TorchBench benchmark suite shows 1.8-2x geomean speedups on 80+ models.
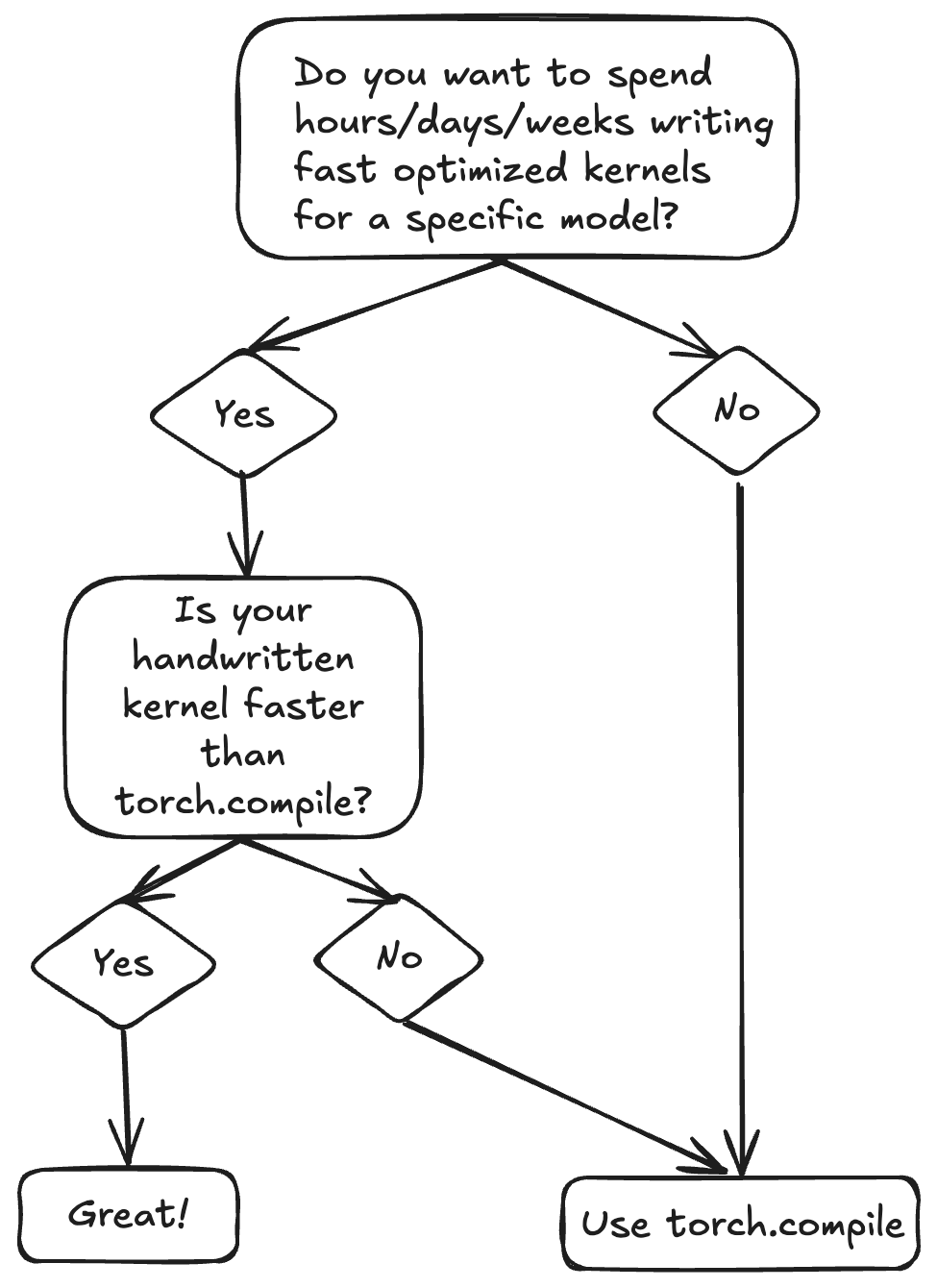
Figure 2: torch.compile gives you fast baseline performance to save YOU development time from tuning model performance.
How torch.compile Works
The torch.compile pipeline consists of two major stages: the frontend (TorchDynamo) and backend (TorchInductor). We’ll give a brief overview, but for more details, please see the official PyTorch 2 paper.
1. Frontend (TorchDynamo): Graph Capture
torch.compile’s frontend is a custom bytecode interpreter. It traces arbitrary Python functions and extracts straight-line torch.fx graphs that consist only of Tensor operations. One of torch.compile’s key features that gives it good coverage over all Python code is graph breaks. Whenever torch.compile sees an operation it cannot support, it doesn’t error. Instead, it ends the current graph being traced, runs the operation, and then begins to trace out a new graph. torch.compile sends each graph that gets traced to the backend for optimization.
In the following code example, torch.save is an unsupported operation: torch.compile doesn’t know how to perform disk I/O. Applying torch.compile to the function f is equivalent to applying torch.compile to the region of compute before the call to torch.save and the region after torch.save.
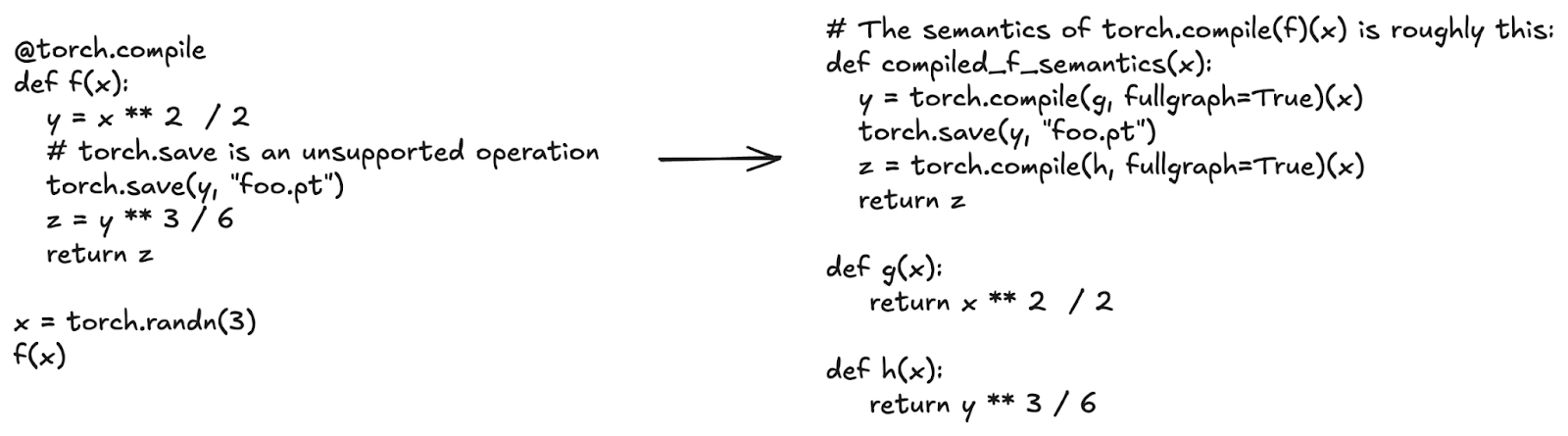
Figure 3: torch.compile captures straight-line graphs of Tensor operations and works around unsupported operations like torch.save.
2. Backend (TorchInductor): Optimization and Kernel Generation
torch.compile’s backend receives graphs from the frontend and optimizes them via graph passes and lowering to optimized C++, triton, or other kernels. It is able to:
- Fuse pointwise and reduction operations
- Auto-tune kernel configurations like block sizes
- Choose between different backends for matmul (cuBLAS, Triton, CUTLASS) and perform prologue and epilogue fusion.
- Use CUDA Graphs to cache and replay kernel launches efficiently
CUDA Graphs is one example where having a compiler is helpful. CUDA Graphs reduce launch overhead but require certain assumptions on your code (e.g. it must only use CUDA operations, input Tensors must have static memory addresses). torch.compile is able to automatically split graphs at unsupported operations to create smaller graphs that are safe to CUDA Graph as well as automatically manage static input buffers.
vLLM Integration
vLLM V1 integrates torch.compile by default for both online and offline inference. You can disable it using -O0 or --enforce-eager, but for most use cases, leaving it on provides performance benefits. See the docs for more details.
Compilation Cache
vLLM compiles models during cold start and saves the artifacts (FX graphs, Triton kernels) in a cache directory (by default, ~/.cache/vllm/torch_compile_cache). On warm start, the artifacts are retrieved from the cache. You can disable the cache via VLLM_DISABLE_COMPILE_CACHE=1 or by deleting the cache directory.
The compiled artifacts and the cache can be reused across machines with the same environment. If you have an autoscaling use case, make sure to generate the cache directory once and share it among instances.
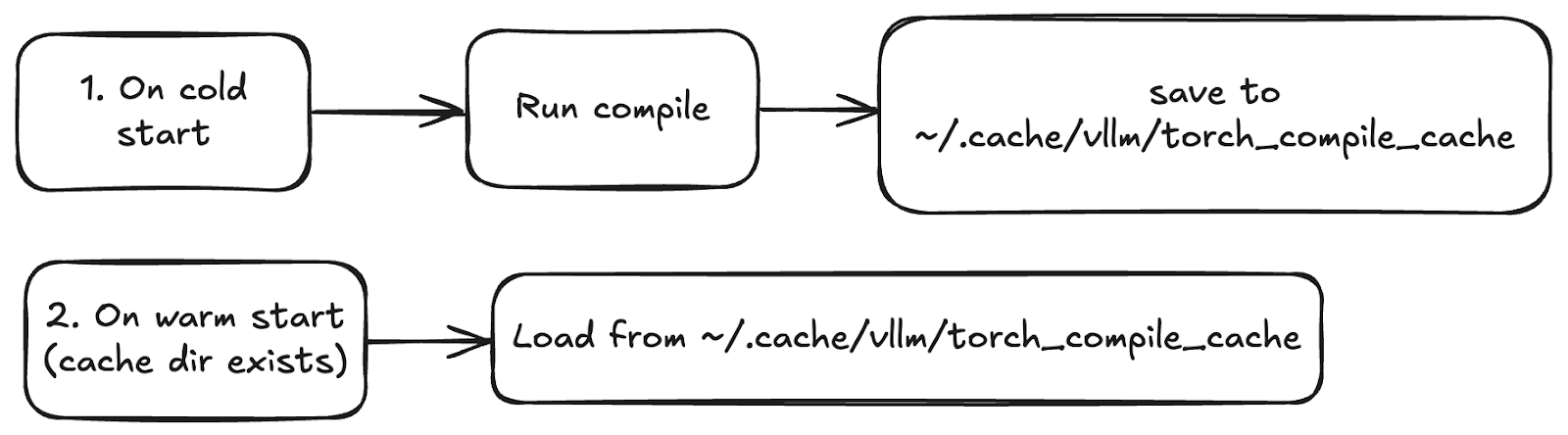
Figure 4: Compiled artifacts are cached after cold start and can be reused across machines to ensure fast, consistent startup when set up correctly.
Dynamic Batch Sizes and Specialization
By default, vLLM compiles a single graph with a dynamic batch size that supports all possible batch sizes. This means one artifact can serve variable input sizes. However, specializing for known batch sizes—like 1, 2, or 4—can yield performance improvements.
Use compile_sizes: [1, 2, 4] in your config to trigger this specialization. Under the hood, this tells torch.compile to compile for these static sizes and possibly perform more autotuning to select the best kernels.

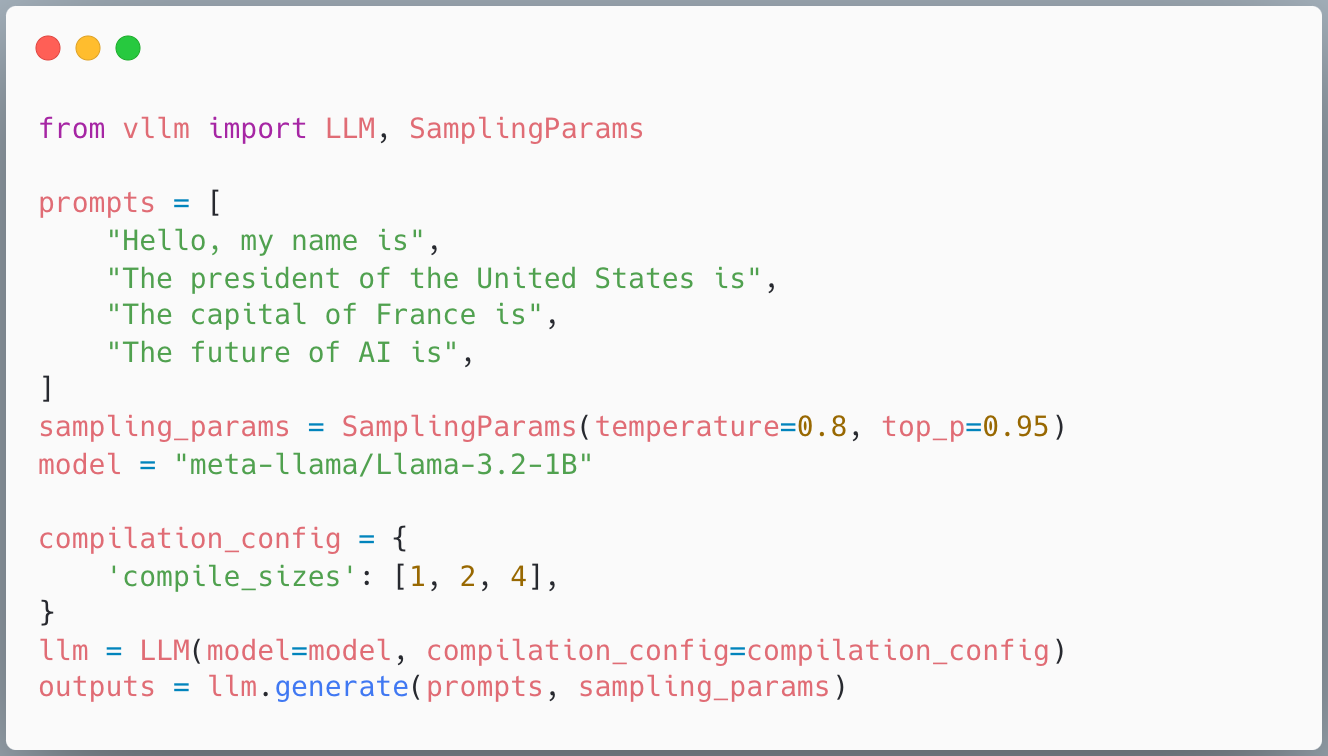
Figure 5: How to specify specializing compilation on specific batch sizes.
Piecewise CUDA Graphs
Not all operations are compatible with CUDA Graphs; for example, cascade attention is not. vLLM works around this by breaking the captured graph into CUDA Graph -safe and -unsafe parts and executing them separately. This gives us the performance benefits of CUDA Graphs without losing correctness.
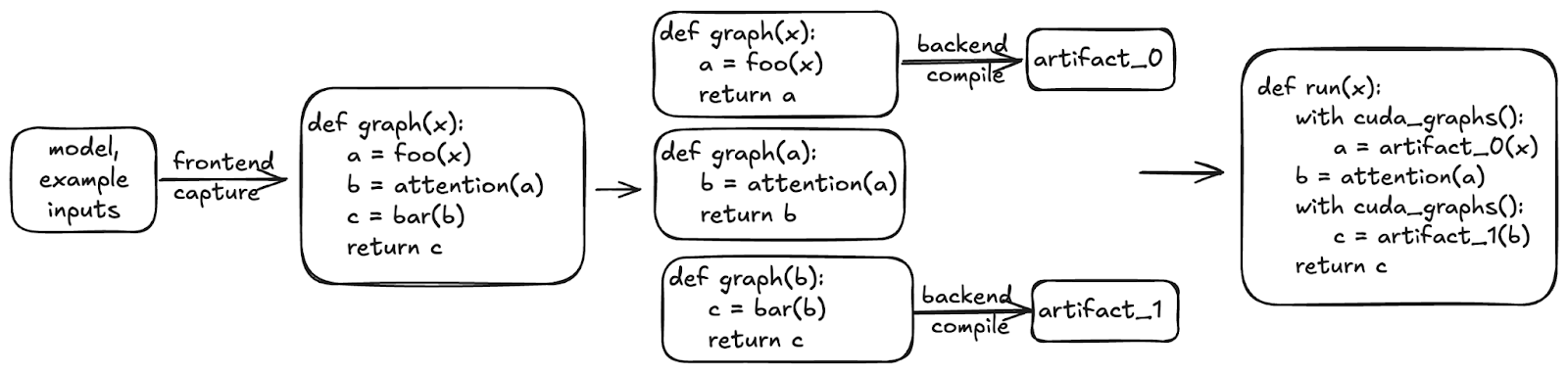
Figure 6: Piecewise CUDA Graphs in vLLM capture and replay supported GPU kernel sequences for low-overhead execution, while skipping unsupported operations like cascade attention.
Custom Compiler Passes in vLLM
While torch.compile includes many built-in optimizations, vLLM adds custom compiler passes that apply additional optimizations to further improve performance. .
Why Custom Passes?
Model authors write declarative, modular code that focuses on correctness and uses clean abstractions, separating higher-level operations into separate submodules and grouping them by layer. However, achieving peak performance often requires breaking those abstractions, like fusing operations across submodules and layers. Rather than rewriting the models, vLLM custom passes rewrite the torch.fx graph.
These passes:
- Fuse memory-bound custom ops like activation functions and quantization
- Add optimizations not present in Inductor (like removing additional no-ops)
Example: SiLU + Quantize Fusion
A common pattern in quantized MLPs is SiLU activation followed by a quantized down-projection linear layer. The quantized linear layer consists of a quantization operation on the input, followed by a quantized matrix multiplication. Individually, SiLU and quantization operations are slow and memory-bound. Using the Inductor pattern matcher utility, the ActivationFusionPass custom pass in vLLM replaces them with a single fused kernel, improving throughput by up to 8 percent.
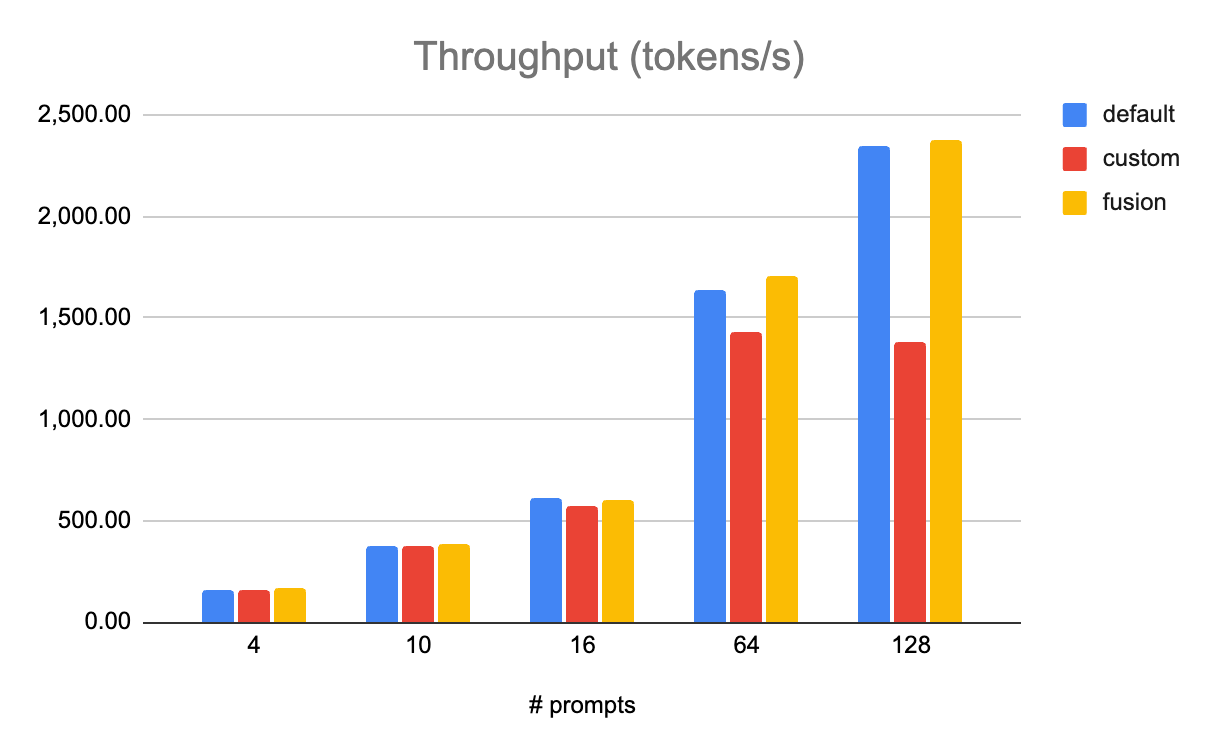
Figure 7: On Llama 3.1 405B quantized to FP8, tested on 8x AMD MI300s, fused kernels (fusion, in yellow) outperformed both default (using torch ops for RMSNorm and SiLU and custom FP8 quant kernel) and custom (unfused custom kernels).
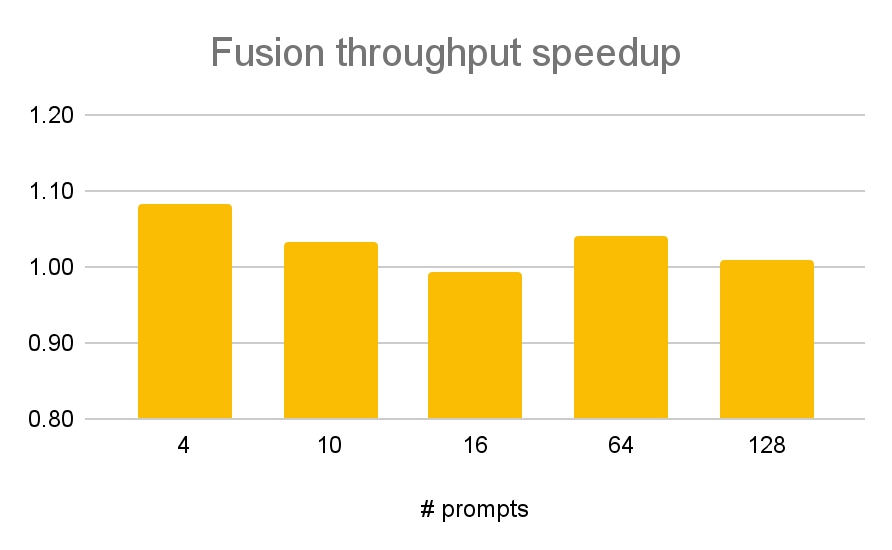
Figure 8: Detailed throughput speedup comparing fusion and default regimes above. If all quantization overhead (8%) was removed via fusion, the theoretical maximum improvement to throughput would be 8%, and we can see that improvement reached in some cases.
Note
Since the office hours, we have added an implementation of quantization using torch operations, which (when compiled by Inductor) is faster than the custom CUDA/ROCm kernel. Because Inductor can fuse those torch ops with the SiLU torch ops automatically, the SiLU+quant and RMSNorm+quant passes are now obsolete in some cases. However, any fusion involving custom ops (attention, collectives, sub-byte quantization) continues to require custom passes. We present the SiLU+Quant example for consistency with the office hours slides and recording, but other fusion passes work in a very similar way.
Example: Sequence Parallelism + Async TP
When using Tensor Parallelism (TP), the linear layer shards the weights and computes incomplete matrix multiplication results, which need to be synchronized across GPUs. When using separate kernels for the compute and communication pieces, we incur communication overhead as the GPUs sit idle while waiting for the network latency of communication results.
Instead, we can overlap computation and communication by using fused GEMM+collective kernels. One example of such kernels are the GEMM+reduce_scatter and all_gather+GEMM kernels. However, to use those, we have to perform intrusive modifications on the fx graph to transform it into a fusion-friendly representation. This includes parallelizing operations between two GEMMs across GPUs.
If we were to implement this kind of optimization in model definitions, we would have to touch every model vLLM supports (there are hundreds of them!). It would be intrusive, increase developer friction, and be unlikely to be accepted into vLLM in the first place. Instead, by implementing the optimization in torch.compile, it is contained to just 2 custom passes and can be turned on using CLI flags, providing better performance for all the models supported by vLLM.
Note
This optimization was implemented in full by a community member @cascade812 who we thank for the incredible contribution. More information on Async TP can be found on the PyTorch blog.
Current and Upcoming Passes
Available Today:
- Fusion passes:
- RMSNorm + Quant (FP8) fusion
- SiLU-Mul + Quant (FP8) fusion
- Attention + Quant (FP8) fusion (up to 7% improvement)
- AllReduce + RMSNorm fusion (up to 15% improvement)
- AllReduce + RMSNorm + Quant (FP8) fusion (up to 8% improvement)
- AllReduce + RMSNorm + Quant (FP4) fusion (up to 10% improvement)
- Sequence Parallelism & Async TP (up to 10% improvement)
- Other passes:
- No-op Elimination: eliminates or simplifies redundant reshape operations
- Fix Functionalization: manually reinplaces auto_functionalized operations to avoid redundant copies and memory use
Coming Soon:
Passes can be added via the PostGradPassManager, CLI (--compilation-config), or by specifying a config object in offline mode. This allows users of vLLM to perform custom graph transformations (kernel substitution or something else) required by their use case without modifying vLLM source code.
Future Work
We’ve come very far on the vLLM-torch.compile integration. Here are some areas that we’re focusing on in the next six months.
Improving stability
The vLLM-torch.compile integration uses many private (begin with an underscore) torch.compile APIs and relies on unstable implementation details. We did this because using the public torch.compile API wasn’t sufficient to fulfill our requirements - vLLM wants fast serving performance and no recompilations during model serving. This has led to issues like weird caching issues, or needing to disable vLLM’s torch.compile cache for certain models. The PyTorch compiler team is working on upstreaming vLLM (and general inference) related features from vLLM to torch.compile and migrating vLLM to using more stable APIs. A lot of these features are already present in torch 2.8, which is coming to vLLM soon!
Improving start-up time
We’ve heard that start-up time is a huge pain point with vLLM torch.compile and CUDAGraphs, especially in the autoscaling setting where one dynamically spins up new machines according to demand. We plan to significantly reduce both cold (first time) and warm (second time and on) start up for vLLM, especially as related to Dynamo and Inductor compilation. Please follow the startup-ux label on GitHub or join the #feat-startup-ux channel on vLLM Slack to stay updated on the progress!
An important UX improvement is the planned revamp of the -O command-line flag. By specifying -O<n> on the vLLM CLI (where n is an integer between 0-3), users will get easier direct control over trading off startup time for performance. While -O0 will perform almost no optimizations and spin up as quickly as possible, -O3 will take much longer but provide the best possible performance.
Custom pass improvements
We are planning on making a few broad improvements to the custom pass mechanism to increase their flexibility and make them easier to write, as well as improve the final performance of applied optimizations:
- Compile multiple dynamic shape
torch.fxgraphs. This would let us specialize the forward pass graph depending on the size of the batch without compiling for each static size separately. More information in the RFC. - Enable matching torch implementations of custom ops. Currently, custom ops (rms_norm, quant, etc.) need to be enabled to allow pattern matching and fusing them, but there might be custom ops that don’t end up getting fused (especially for quant which happens 4x per layer). Those ops are slower than their torch equivalents, which reduces the benefits of fusion. We have a working prototype that pattern-matches torch implementations of custom ops, promising further performance improvements.
Experimental torch.compile backend integration
We are also exploring an experimental MPK/Mirage compiler integration. MPK is a precision-scheduling megakernel compiler, meaning it produces a single kernel for the whole model forward pass, which can further reduce CPU overheads and eliminate kernel launch overhead as compared to CUDA Graphs. More information on the proposed integration in the RFC.
Other performance improvements
The goal of vLLM’s torch.compile integration is provide good baseline performance to avoid needing to write and maintain a significant amount of custom kernels. We will continue to maintain and improve performance. Some highlights of work-in-progress work includes:
- Improved FlexAttention support. FlexAttention is an API that allows the use of different attention variants without needing to write a custom attention kernel for each. Under the hood, it uses torch.compile to produce a custom triton template.
- Full CUDA Graphs support for Flash Attention v2 and FlashInfer. Full CUDAGraphs have less overhead than piecewise CUDA Graphs and should improve performance in those high-overhead settings.
Conclusion
torch.compile provides a powerful and accessible way to accelerate PyTorch models. In vLLM, it’s a core part of the inference pipeline. Combined with caching, dynamic shape support, CUDA Graphs, and custom passes, it enables efficient, scalable LLM serving across any environment.
As the compiler stack matures and support for new hardware expands, torch.compile and vLLM will continue to push the boundaries of inference performance—while keeping model development clean and modular. Read more about torch.compile in the PyTorch documentation and the vLLM documentation, and join the #sig-torch-compile channel on vLLM Slack to ask questions, share feedback, and contribute your own custom passes!